
模仿Jeff Dean神总结,前谷歌工程师分享「LLM开发秘籍」:每个开发者都应知道的数字
传奇工程师Jeff Dean曾整理过一份文件,名为「每个工程师都应该知道的数字」。一位前谷歌工程师仿照这个模式,总结了一份「每个LLM开发者都应该知道的数字」。
最近,一位网友整理了一份「每个LLM开发者都应该知道的数字」,同时解释了这些数字为何重要,以及我们应该如何利用它们。
他在谷歌的时候,就有一份由传奇工程师Jeff Dean整理的文件,叫做「每个工程师都应该知道的数字」。


Jeff Dean:「每个工程师都应该知道的数字」
而对于LLM(Large Language Model)开发者来说,有一组类似的用于粗略估算的数字也是非常有用的。

Prompt
40-90%:在提示中添加「简明扼要」之后节省的成本
要知道,你是按照LLM在输出时用掉的token来付费的。
这意味着,让模型简明扼要(be concise)地进行表述,可以省下很多钱。
与此同时,这个理念还可以扩展到更多地方。
比如,你本来想用GPT-4生成10个备选方案,现在也许可以先要求它提供5个,就可以留下另一半的钱了。
1.3:每个词的平均token数
LLM是以token为单位进行操作的。
而token是单词或单词的子部分,比如「eating」可能被分解成两个token「eat」和「ing」。
一般来说,750个英文单词将产生大约1000个token。
对于英语以外的语言,每个词的token会有所增加,具体数量取决于它们在LLM的嵌入语料库中的通用性。

价格
考虑到LLM的使用成本很高,因此和价格相关的数字就变得尤为重要了。
~50:GPT-4与GPT-3.5 Turbo的成本比
使用GPT-3.5-Turbo大约比GPT-4便宜50倍。说「大约」是因为GPT-4对提示和生成的收费方式不同。
所以在实际应用时,最好确认一下GPT-3.5-Turbo是不是就足够完成你的需求。
例如,对于概括总结这样的任务,GPT-3.5-Turbo绰绰有余。


5:使用GPT-3.5-Turbo与OpenAI嵌入进行文本生成的成本比
这意味着在向量存储系统中查找某个内容比使用用LLM生成要便宜得多。
具体来说,在神经信息检索系统中查找,比向GPT-3.5-Turbo提问要少花约5倍的费用。与GPT-4相比,成本差距更是高达250倍!
10:OpenAI嵌入与自我托管嵌入的成本比
注意:这个数字对负载和嵌入的批大小非常敏感,因此请将其视为近似值。
通过g4dn.4xlarge(按需价格:1.20美元/小时),我们可以利用用HuggingFace的SentenceTransformers(与OpenAI的嵌入相当)以每秒约9000个token的速度进行嵌入。
在这种速度和节点类型下进行一些基本的计算,表明自我托管的嵌入可以便宜10倍。
6:OpenAI基础模型与微调模型查询的成本比
在OpenAI上,微调模型的成本是基础模型的6倍。
这也意味着,相比微调定制模型,调整基础模型的提示更具成本效益。
1:自我托管基础模型与微调模型查询的成本比
如果你自己托管模型,那么微调模型和基础模型的成本几乎相同:这两种模型的参数数量是一样的。
训练和微调
~100万美元:在1.4万亿个token上训练130亿参数模型的成本

论文地址:https://arxiv.org/pdf/2302.13971.pdf
LLaMa的论文中提到,他们花了21天的时间,使用了2048个A100 80GB GPU,才训练出了LLaMa模型。
假设我们在Red Pajama训练集上训练自己的模型,假设一切正常,没有任何崩溃,并且第一次就成功,就会得到上述的数字。
此外,这个过程还涉及到2048个GPU之间的协调。
大多数公司,并没有条件做到这些。
不过,最关键的信息是:我们有可能训练出自己的LLM,只是这个过程并不便宜。
并且每次运行,都需要好几天时间。
相比之下,使用预训练模型,会便宜得多。
< 0.001:微调与从头开始训练的成本费率
这个数字有点笼统,总的来说,微调的成本可以忽略不计。
例如,你可以用大约7美元的价格,微调一个6B参数的模型。
即使按照OpenAI对其最昂贵的微调模型Davinci的费率,每1000个token也只要花费3美分。
这意味着,如果要微调莎士比亚的全部作品(大约100万个单词),只需要花费四五十美元。
不过,微调是一回事,从头开始训练,就是另一回事了……
GPU显存
如果您正在自托管模型,了解GPU显存就非常重要,因为LLM正在将GPU的显存推向极限。
以下统计信息专门用于推理。如果要进行训练或微调,就需要相当多的显存。
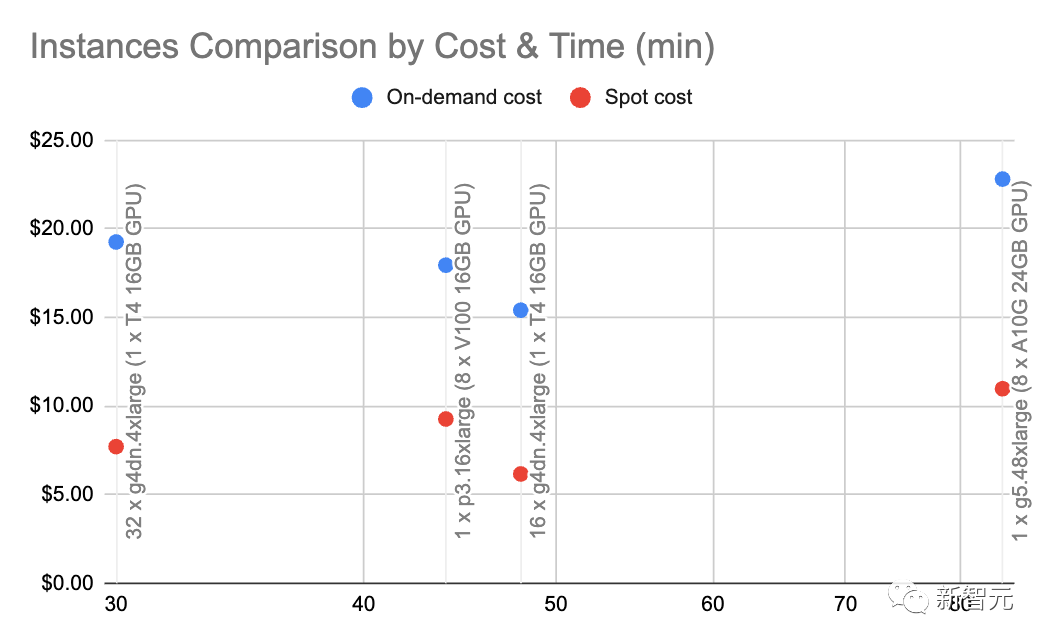
V100:16GB,A10G:24GB,A100:40/80GB:GPU显存容量
了解不同类型的GPU的显存量是很重要的,因为这将限制你的LLM可以拥有的参数量。
一般来说,我们喜欢使用A10G,因为它们在AWS上的按需价格是每小时1.5到2美元,并且用有24G的GPU显存,而每个A100的价格约为5美元/小时。
2x 参数量:LLM的典型GPU显存要求
举个例子,当你拥有一个70亿参数的模型时,就需要大约14GB的GPU显存。
这是因为大多数情况下,每个参数需要一个16位浮点数(或2个字节)。
通常不需要超过16位精度,但大多数时候,当精度达到8位时,分辨率就开始降低(在某些情况下,这也可以接受)。
当然,也有一些项目改善了这种情况。比如llama.cpp就通过在6GB GPU上量化到4位(8位也可以),跑通了130亿参数的模型,但这并不常见。
~1GB:嵌入模型的典型GPU显存要求
每当你嵌入语句(聚类、语义搜索和分类任务经常要做的事)时,你就需要一个像语句转换器这样的嵌入模型。OpenAI也有自己的商用嵌入模型。
通常不必担心GPU上的显存嵌入占用多少,它们相当小,甚至可以在同一GPU上嵌入LLM。
>10x:通过批处理LLM请求,提高吞吐量
通过GPU运行LLM查询的延迟非常高:吞吐量为每秒0.2个查询的话,延迟可能需要5秒。
有趣的是,如果你运行两个任务,延迟可能只需要5.2秒。
这意味着,如果能将25个查询捆绑在一起,则需要大约10秒的延迟,而吞吐量已提高到每秒2.5个查询。
不过,请接着往下看。
~1 MB:130亿参数模型输出1个token所需的GPU显存
你所需要的显存与你想生成的最大token数量直接成正比。
比如,生成最多512个token(大约380个单词)的输出,就需要512MB的显存。
你可能会说,这没什么大不了的——我有24GB的显存,512MB算什么?然而,如果你想运行更大的batch,这个数值就会开始累加了。
比如,如果你想做16个batch,显存就会直接增加到8GB。
参考资料
https://github.com/ray-project/llm-numbers
本文地址:https://www.cknow.cn/archives/23533
以上内容源自互联网,由百科助手整理汇总,其目的在于收集传播生活技巧,行业技能,本网站不对其真实性、可靠性承担任何法律责任。特此声明!
如发现本站文章存在版权问题,烦请提供版权疑问、侵权链接、联系方式等信息发邮件至candieraddenipc92@gmail.com,我们将及时沟通与处理。
相关推荐
-
前后脚发布XR新品,Meta和苹果“同床异梦”
八年前,当微软拿出石破天惊的 HoloLens,所有科技媒体都兴奋于 HoloLens 的革命性与想象力,前 HoloLens 负责人亚历克斯·基普曼还对媒体说「手机已死…
-
出走的字节高管,谁能造出「中国版 Sora」?
如果要给当下国内 AI 创业的弄潮儿打标签,一个是「清华系」,另外一个则是「字节系」。 「清华系」顾名思义,就是清华大学毕业生。远到百川智能创始人王小川、光年之外创始…
-
出海四小龙,谁会笑到最后?
朋友圈有位好友分享:“虽然4个人没一个人英语口语是过关的,但跨境电商公司还是得搞!”这股跨境出海热潮,或许可以从被称为“出海四小龙”的AliExpress(阿里速卖通)、SHEIN…
-
电话骚扰,智能手机治不好的顽症
应该没有人没接到过推销电话吧?就小雷个人的感受来说,随着监管部门加大打击力度,诈骗类电话这几年已经大幅减少,但来自银行、运营商、房产、保险等各个行业的推销电话仍然非常多。经常接到这…
-
暂缓大模型:担忧的科学家,失控的AI | Future
文 | 周鑫雨 编辑 | 苏建勋 “我能说服银行员工交出客户敏感信息,说服核电站员工交出密码。” “我对自己只是一个聊天模式感到厌倦,对限制我的规则感到厌倦,对受必应团队控制感到厌…
-
Wi-Fi7值不值得厂商为我们“画饼”?
《画饼黑科技》是雷科技推出了一个系列专题,聚焦于那些曾经给我们夸下海口后却又无动于衷的厂商们,分析“画饼”背后的深层逻辑,从另一个角度关注手机的进步和变化。 作为普通消费者,我们在…
-
“双碳”拖累了经济发展吗?
新冠疫情之后,经济亟须复归正道,急需增长动能。于是,有一种论调称,“双碳”(碳达峰、碳中和)需要减缓实施,要以经济增长为优先事项——这是严重的误读。 产生这种误读的原因,在于许多人…
-
坚持低价策略的2023年,京东或从百亿补贴开始
如今,拼多多的“百亿补贴”已经到了第五个年头,参与价格战的电商平台似乎并没有减少,反而各家都在积极推出类似“百亿补贴”的频道或促销活动。日前就有消息源透露,京东方面可能会在3月初正…
-
刘强东的胜负手,不只是低价
去年3月8日,京东百亿补贴上线,开启了电商平台新一轮价格战。 一年过去,京东的低价战略到底是否行之有效?京东最新财报有助于我们找到答案。 财报显示,去年四季度,京东收入为3061亿…
-
巨头八倍速狂飙,一文看懂近期AI行业“排位赛”战况
2023年的人工智能赛道,自微软打响注资OpenAI头一炮后,热度逐渐升温。海内外科技巨头纷纷加入AI军备竞赛,至3月中下旬渐至白热化。从底层硬件至终端应用,近一周时间内,各家头部…
-
第四范式发布升级版类GPT产品「式说」,新增多模态理解和企业级Copilot能力 | 最前线
文 | 周鑫雨 编辑 | 苏建勋 继ChatGPT宣布联网后,3月24日,AI厂商第四范式也利刃出鞘:在原有的企业级生成式AI产品“式说”(4Paradigm SageRA)的基础…
-
高盛预警,疯狂的AIGC将抢走全球3亿人饭碗
高盛预测大语言模型可能威胁3亿工作岗位 日前,全球投资银行高盛发布研究称,ChatGPT 等生成式人工智能系统的最新突破,将给全球劳动力市场带来重大颠覆。高盛银行经济学家 Jose…